
네이버 영화리뷰 데이터 전처리.
기본 데이터 다운
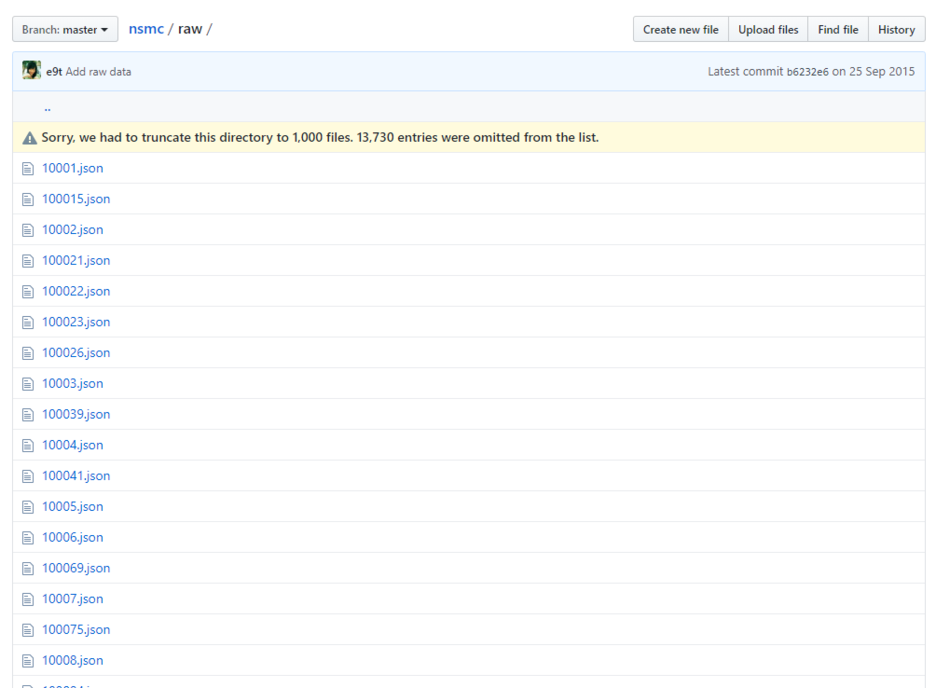
해당 github에서 raw 폴더 데이터를 다운 받는다.
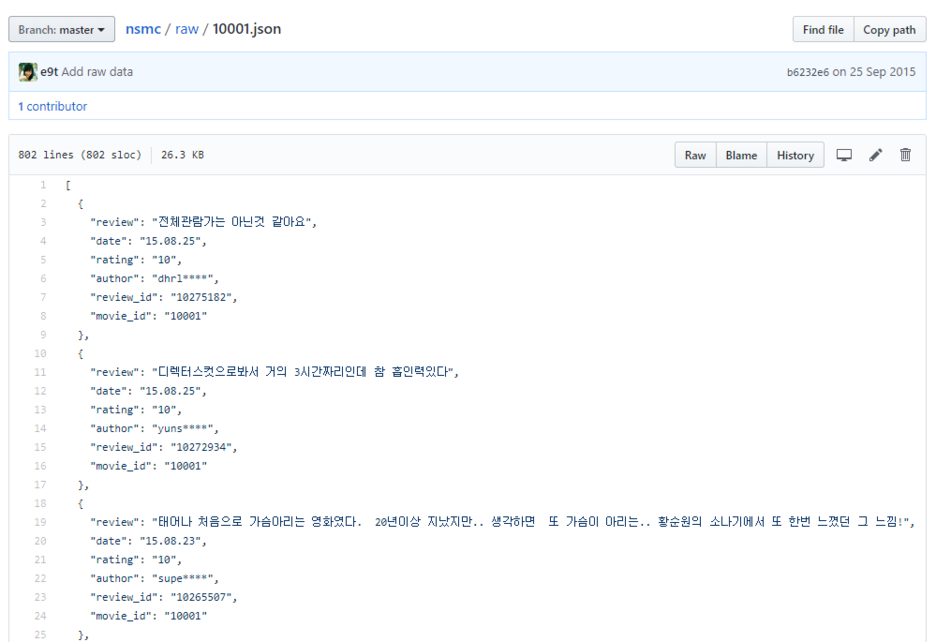
(그림1)을 보면 raw 폴더 내부에는 수천개의 json 파일이 있고 json 파일의 (그림2)와 같은 형태로 구성되어 있다.
데이터 가공
여러개의 json 파일을 하나의 CSV 파일로 합친다. 그리고 해당 CSV 파일을 학습 데이터로 사용한다.
data_sum.py를 사용해 하나의 CSV 파일로 만들었다.
import json |
import csv |
import os |
''' |
[1] 목적 |
raw 폴더에 존재하는 데이터를 하나의 파일로 합쳐준다. |
json 파일로 분할되어 있는 데이터를 필요한 부분만 가져와 하나의 CSV 파일로 합친다. |
그리고 해당 CSV 파일을 학습 데이터로 사용한다. |
|
[2] 구현 흐름 |
1. 해당 폴더 내에 있는 모든 파일명을 읽는다. |
2. 각 json파일을 open하여 필요한 데이터('review', 'rating')를 가져온다. |
3. 만약, 해당 json 파일이 첫번째로 open하는 것이면 output.csv 파일을 만들어 write를 하고 |
첫번째로 open하는 것이 아니면 기존에 만들어져 있는 파일에 add를 한다. |
4. output.csv 파일의 데이터가 몇개인지 표시해준다. |
|
[3] search 함수 |
=> 해당 폴더의 모든 파일을 읽어 하나의 파일로 합친다. |
1st para : json파일이 들어 있는 폴더의 위치 |
2nd para : output 파일의 경로 |
''' |
global first_file # 첫번째 json 파일을 check 하는 flag |
def search(input_folder_directory, output_folder_directory): |
filenames = os.listdir(input_folder_directory) # [2-1] 해당 경로에 있는 파일들을 모두 읽는다. |
first_file = True # 처음 시작할 때는 True로 설정한다. |
for filename in filenames: |
full_filename = os.path.join(input_folder_directory, filename) |
print(full_filename) |
with open(full_filename, encoding='utf-8') as data_file: |
data = json.load(data_file) # [2-2] 파일을 open 한다. |
if first_file: # [2-3] 해당 json 파일이 첫번째로 오픈 하는 경우에 새로운 파일을 만들어 write 한다. |
f = open(output_folder_directory, 'w', encoding='utf-8', newline='') |
wr = csv.writer(f) |
for i in range(0, len(data)): |
review = data[i]['review'] |
rating = data[i]['rating'] |
wr.writerow([review, rating]) |
f.close() |
first_file = False |
else: # [2-3] 해당 json 파일이 첫번째로 오픈 하는 경우가 아닌 경우 현재 파일에 add한다. |
add_f = open(output_folder_directory, 'a' , encoding='utf-8', newline='') |
wr = csv.writer(add_f) |
for i in range(0, len(data)): |
review = data[i]['review'] |
rating = data[i]['rating'] |
wr.writerow([review, rating]) |
add_f.close() |
# read_csv = open(output_folder_directory, 'r', encoding='utf-8') # [2-4] 현재 파일에 데이터가 몇 개인지를 출력해준다. |
# print(len(read_csv.readlines())) |
# search 함수를 실행시킨다. |
search("../../naver movie review/data/raw/", "../data/data.csv") |
가공 결과
- 가공을 완료하면 ( 그림3 )과 같은 형태가 된다.
