BERT 소개
Google 에서 만든 Word Embedding 기법 ( 2018. 10. 11 논문 공개 )
NLP 11개 Task에 SOTA(State of the Arts)를 기록했으며, SQuAD v1.1에서는 인간보다 더 높은 정확도를 보여 주목을 받고 있다.
최근까지 GLUE NLP Task 에서 1등을 차지했었다. ( 그러나 MT-DNN에 1등을 뺏겼다. )
Pre-trained 기반 딥러닝 언어 모델
BERT 개발자들의 접근방식 : (1) 범용 솔루션을 (2) 스케일러블 한 형태로 구현해서 (3) 많은 머신리소스로 훈련해서 성능을 높인다
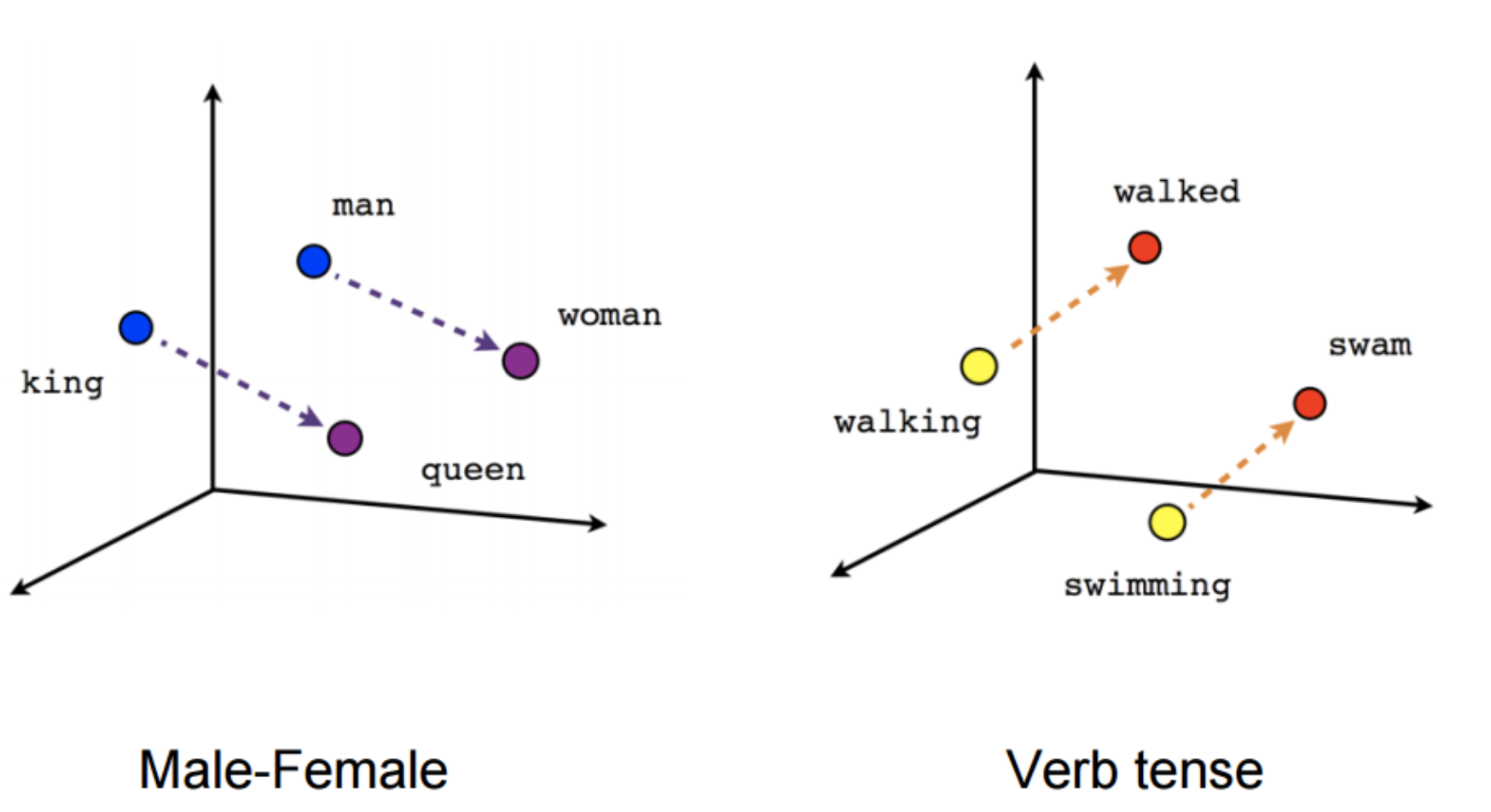
BERT는 Contextual Embedding 방법에 속한다. (Contextualised Word Embedding은 단어마다 벡터가 고정되어 있지 않고 문장마다 단어의 Vector가 달라지는 Embedding 방법을 뜻한다 대표적으로 ELMo, GPT, BERT가 있다.)
