후기
- Keras는 Tensorflow랑 다르게 크게 변경할 것이 없다.
Keras는 정말 사용하기 쉬운 것 같다.
설치
- anaconda 에 가상 환경 만들어주기
anaconda prompt에서 다음의 명령어를 실행해준다.
conda create --name kerasactivate keras
keras-gpu 버전을 설치한다.
conda install keras-gpu
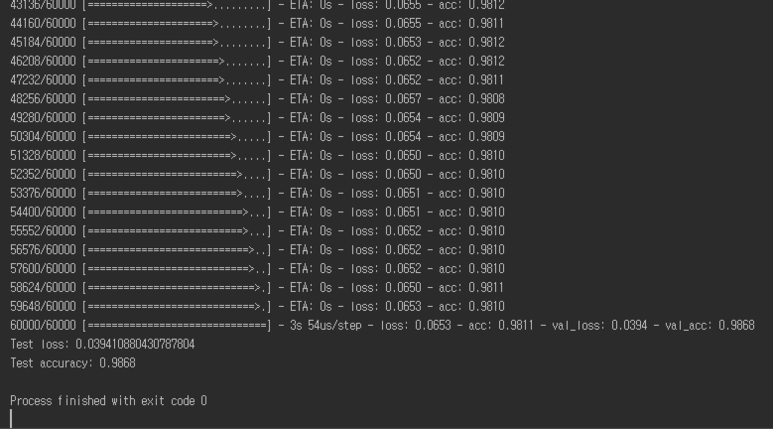
CPU와 GPU 속도 비교
CPU : Intel(R) Core(TM) i7-8700K CPU @ 3.7GHz
GPU : NVIDIA GeForce GTX 1080Ti
사용 코드 : CNN을 이용한 MNIST 데이터 분류 코드
'''Trains a simple convnet on the MNIST dataset. |
Gets to 99.25% test accuracy after 12 epochs |
(there is still a lot of margin for parameter tuning). |
16 seconds per epoch on a GRID K520 GPU. |
''' |
from __future__ import print_function |
import keras |
from keras.datasets import mnist |
from keras.models import Sequential |
from keras.layers import Dense, Dropout, Flatten |
from keras.layers import Conv2D, MaxPooling2D |
from keras import backend as K |
batch_size = 128 # 배치 사이즈 128로 설정. |
num_classes = 10 # 정답 라벨링 개수 ( 0 ~ 10 ) |
epochs = 3 # Epoch 반복 회숫 3회로 설정 |
# input image dimensions |
img_rows, img_cols = 28, 28 # 이미지 가로 세로 배열. |
# MNIST 데이터 불러오기 |
(x_train, y_train), (x_test, y_test) = mnist.load_data() |
if K.image_data_format() == 'channels_first': |
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols) |
x_test = x_test.reshape(x_test.shape[0], 1, img_rows, img_cols) |
input_shape = (1, img_rows, img_cols) |
else: |
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 1) |
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 1) |
input_shape = (img_rows, img_cols, 1) |
x_train = x_train.astype('float32') |
x_test = x_test.astype('float32') |
x_train /= 255 |
x_test /= 255 |
print('x_train shape:', x_train.shape) |
print(x_train.shape[0], 'train samples') |
print(x_test.shape[0], 'test samples') |
# convert class vectors to binary class matrices |
y_train = keras.utils.to_categorical(y_train, num_classes) |
y_test = keras.utils.to_categorical(y_test, num_classes) |
model = Sequential() |
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=input_shape)) # Input Layer : 32개의 필터를 가진다. |
model.add(Conv2D(64, (3, 3), activation='relu')) # 첫번째 hidden layer이며 64개의 필터를 가진다. |
model.add(MaxPooling2D(pool_size=(2, 2))) # Pooling Layer를 의미한다. |
model.add(Dropout(0.25)) # Dropout을 0.25로 하여 overfitting을 방지한다. |
model.add(Flatten()) # 데이터를 1차원으로 바꿔주는 Layer. 아래의 fully_connected_layer에 연결해주기 위해 1차원으로 바꾸어준다. |
model.add(Dense(128, activation='relu')) # Dense는 Fully Connected Layer를 의미한다. |
model.add(Dropout(0.5)) # Dropout은 0.5로 하여 overfitting을 방지한다. |
model.add(Dense(num_classes, activation='softmax')) # Output Layer를 의미하며 activation은 softmax로 분류흘 한다. |
model.summary() # 모델의 요약을 보여준다. |
model.compile(loss=keras.losses.categorical_crossentropy, |
optimizer=keras.optimizers.Adadelta(), |
metrics=['accuracy']) |
model.fit(x_train, y_train, |
batch_size=batch_size, |
epochs=epochs, |
verbose=1, |
validation_data=(x_test, y_test)) |
score = model.evaluate(x_test, y_test, verbose=0) |
print('Test loss:', score[0]) |
print('Test accuracy:', score[1]) |
- CPU 결과 : 167초
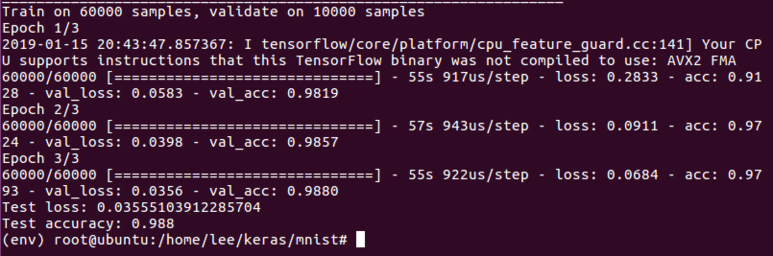
- GPU 결과 : 9초