- tf idf 설명.
소개
TF-IDF란 단어의 빈도와 역문서 빈도를 사용하여 단어들마다 가중치를 부여하는 방법이다.
TF ( Term Frequency ) : 특정 문서 d에서 특정 단어 t의 등장 회수
ex) “과자”라는 단어가 문서3에서 100번 등장했다.DF( Document Frequency ) : 특정 단어 t가 등장한 문서의 수
ex) “과자”라는 단어가 문서2와 문서3에서 언급되었다.
이럴 경우 DF는 2이다. 몇 개의 문서에서 언급되었는지를 알아야 한다.IDF ( Inverse Document Frequency ) : DF(t)에 반비례하는 수
분모에 1을 추가해주는 이유는 df가 0일 경우에 분모가 0이 되기 때문이다.
분자의 n은 전체 문서의 개수를 의미한다.
ex) “과자”라는 단어가 문서1에서 0번, 문서2에서 100번, 문서3에서 200번 언급되었다고 가정하자.
log(분자 : 3 / 분모 : 1+2) 가 된다.
여러 문서에서 자주 사용하는 단어일수록 값이 0에 가까워지기 때문에 TF x IDF한 값이 작아지게 된다.
예시
전체 소스코드는 github에 공개하였다.
sentence_list = [‘오늘은 즐거운 하루입니다’, ‘오늘은 비가 올 것 같은데 내일은 비가 안 왔으면 좋겠네요.’, ‘내일도 비가 올 것 같아요’ ]
BoW
앞에서 진행 했던 BoW로 위의 sentence_list를 표현하면 다음과 같다.
단어수가 한 글자인 것은 제외해서 vector를 구성하였다.
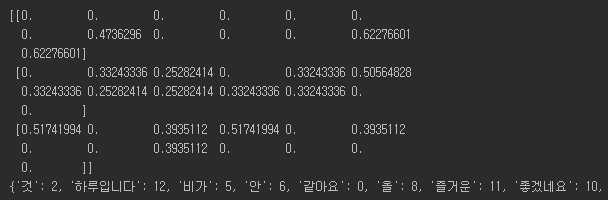
TF-IDF ver.1
가장 basic한 형태의 TF-IDF이다.
위의 BoW에서 단어의 가중치를 Vector로 표현을 하였다.
TF-IDF ver.2
한 글자인 단어들도 Vector에 포함하였다.
TF-IDF ver.3
위의 TF-IDF에서 ngram_range=(2, 3)를 추가하였다.
단어를 2글자 or 3글자 단위로 묶어 처리하였다.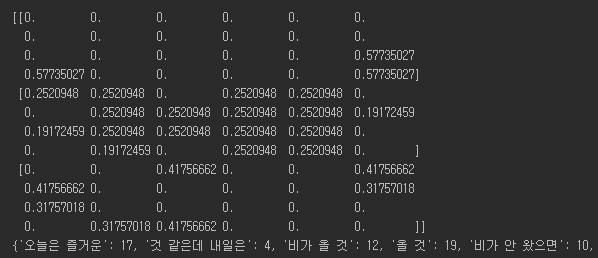
TF-IDF ver.4
ngram_range=(2, 3)를 추가하고 analyzer=’char’로 변경하였다.
char로 변경하였기 때문에 단어가 아닌 글자가 기준이 된다.
생각
TF-IDF 의 개념과 사용방법은 생각보다 쉽다.
문제는 이러한 단어의 가중치들이 알고리즘에 어떻게 사용되는지를 이해하는 것이 중요한 것 같다.
뭔가 단어에다가 가중치를 준다고 하면 더 좋을 것 같아보인다.
하지만 실제 성능이 향상하는지 확인해봐야 알 것 같다.
