서론
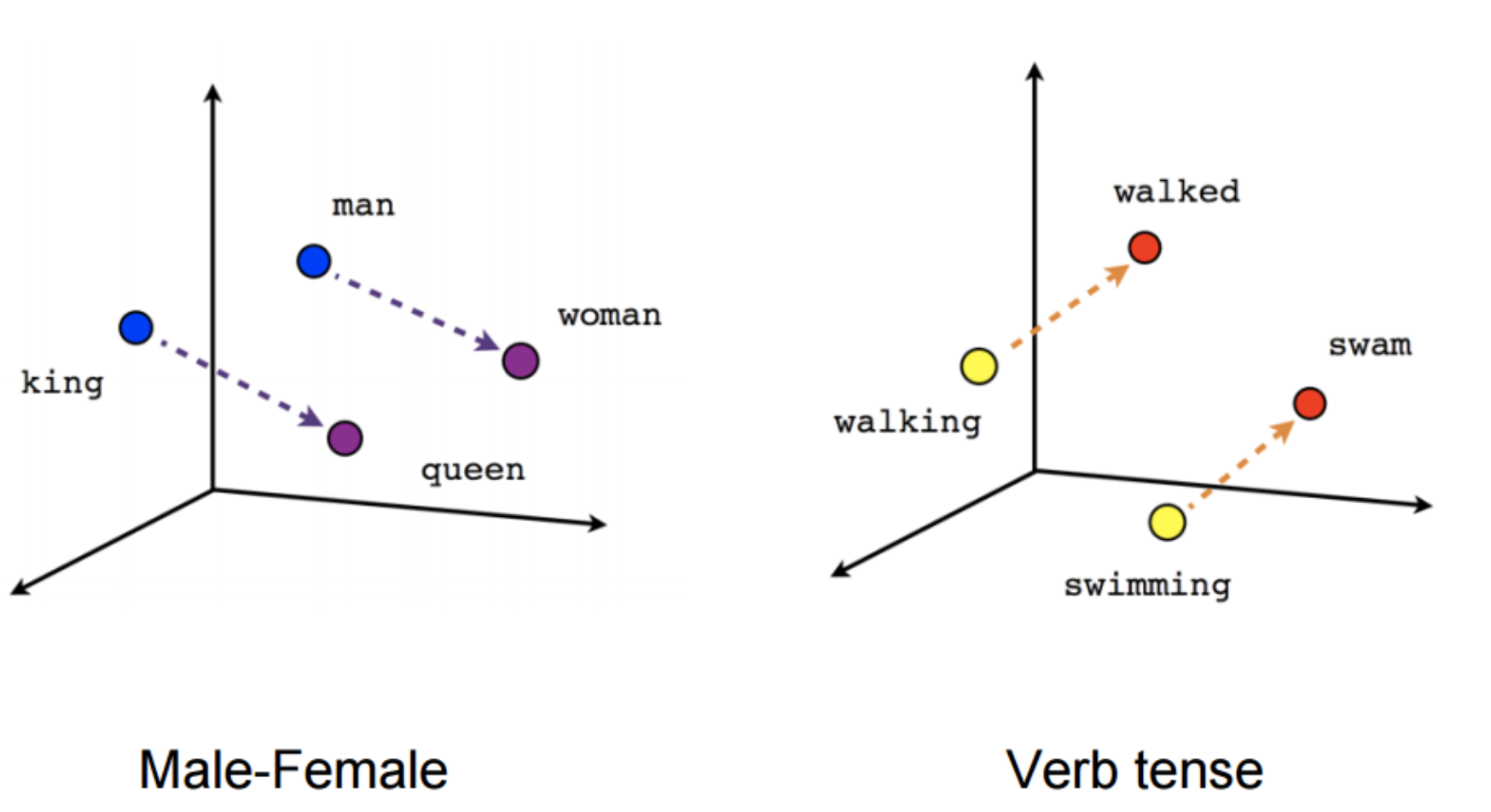
Word2vec에 대한 설명은 word_embedding/word2vec에 있다.
한겨레 신문의 정치 기사 대략 1000개를 수집하였다.
위의 데이터를 사용해 word2vec을 구현한다.코드는 github에 공개.
[URL] : https://github.com/vhrehfdl/Blog/tree/master/word_embedding
총 3개의 python 파일로 구성되어 있다.
구성
make_corpus.py
한겨레 기사는 여러 문장으로 단락이 구성되어져 있다.
그래서 문장 by 문장으로 잘라서 정리를 한 후 corpus.txt라는 파일을 만들어준다.
make_token.py
위에서 만든 corpus.txt라는 문장이 담겨있는 파일을 Token으로 변환시켜 corpus_token.txt라는 파일을 만든다.
영어는 NLTK를 활용하여 문장을 Token으로 나누어준다.
한국어는 형태소 분석기를 사용해 문장을 형태소 단위로 나누어 준다.
여기서는 Konlpy 라이브러리의 Komoran 모듈을 사용해 문장을 Token으로 변환시켜주었다.
make_model.py
- Token으로 저장된 파일을 불러와 gensim의 word2vec에 입력한다.
결과
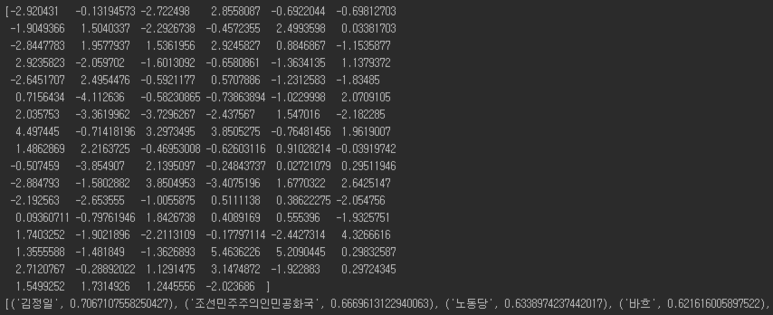
vector의 dimension은 100차원으로 정의하였다.
그래서 “서울”이라는 단어의 embedding은 아래와 같고
유사한 단어는 경기도, 강남구, 중구 등이 나왔다.
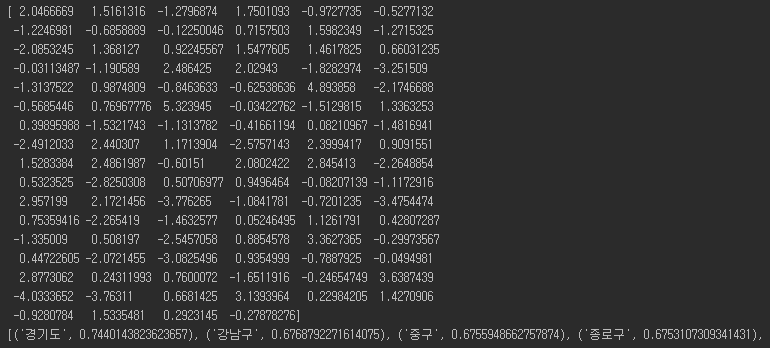
- “김정일”이라는 단어를 넣으면 다음과 같은 결과가 나온다.