BERT 소개
Google 에서 만든 Word Embedding 기법 ( 2018. 10. 11 논문 공개 )
NLP 11개 Task에 SOTA(State of the Arts)를 기록했으며, SQuAD v1.1에서는 인간보다 더 높은 정확도를 보여 주목을 받고 있다.
최근까지 GLUE NLP Task 에서 1등을 차지했었다. ( 그러나 MT-DNN에 1등을 뺏겼다. )
Pre-trained 기반 딥러닝 언어 모델
BERT 개발자들의 접근방식 : (1) 범용 솔루션을 (2) 스케일러블 한 형태로 구현해서 (3) 많은 머신리소스로 훈련해서 성능을 높인다
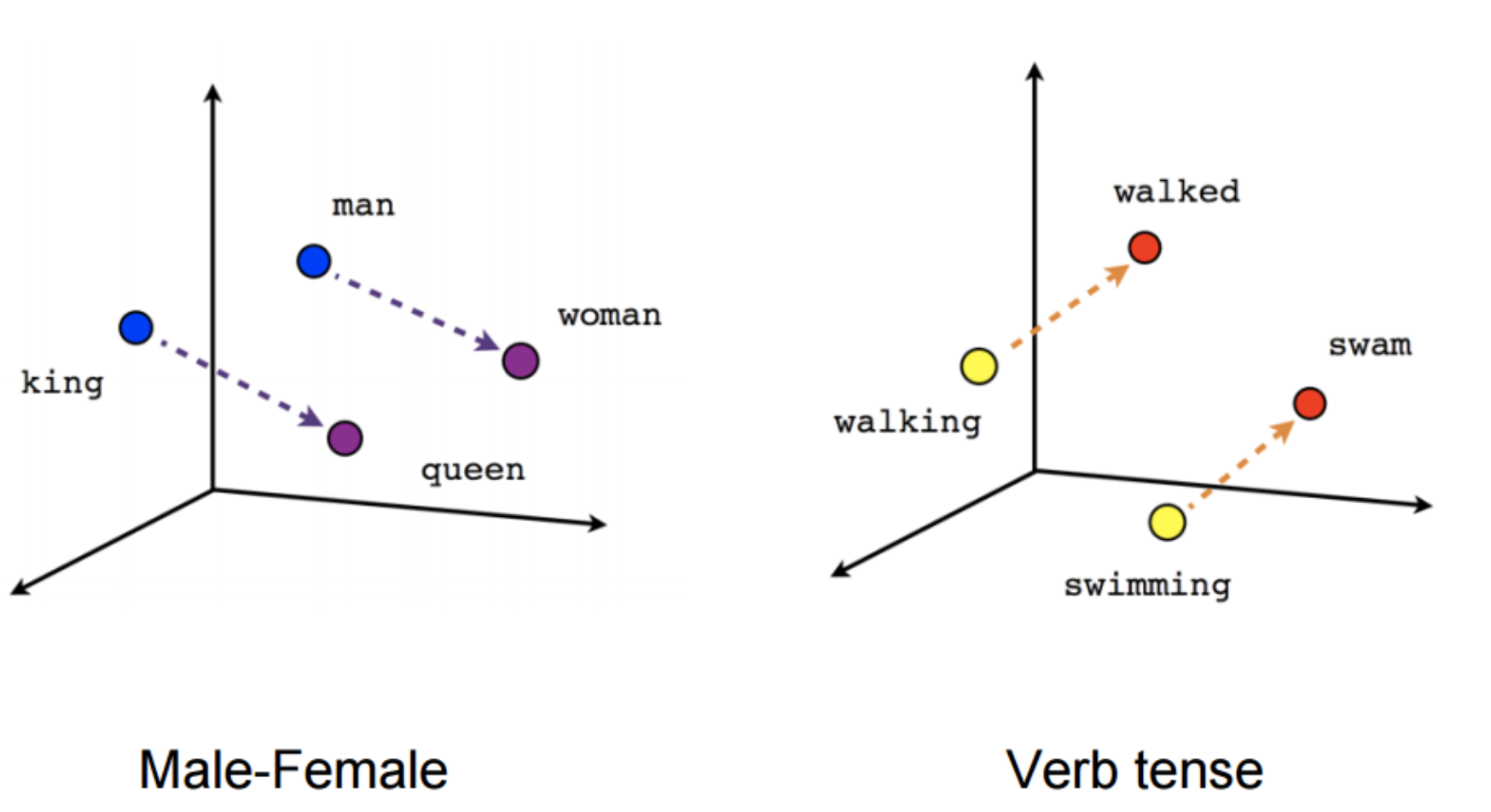
BERT는 Contextual Embedding 방법에 속한다. (Contextualised Word Embedding은 단어마다 벡터가 고정되어 있지 않고 문장마다 단어의 Vector가 달라지는 Embedding 방법을 뜻한다 대표적으로 ELMo, GPT, BERT가 있다.)
Static Word Embedding 문제점
Static Word Embedding은 단어마다 벡터가 고정되어 있는 방법을 뜻하면 대표적으로 Word2vec, Fasttext, Glove이 존재한다.
Problem : 단어의 Vector가 모든 문맥에서 동일하다.
에를 들어 “배를 타고 떠났다”와 “맛있는 배를 먹었다”라는 문장에서 “배를”은 같은 벡터 값을 가진다.
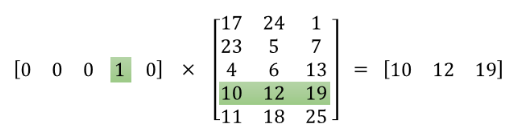
“배를” 이란 단어는 One-hot Encoding 방식으로 표현하면 [ 0 0 0 1 0 ]의 값을 가진다.
첫번째 문장에서도 [ 0 0 0 1 0 ]을 가지고 두번째 문장에서도 [ 0 0 0 1 0 ]을 가진다.
모든 문장에서 고정된 One-hot Encoding 값을 가진다!모든 단어들이 고정된 One-hot Encoding을 가지는 상태에서 Weight Vector를 곱하면 모든 문장에서 똑같은 Vector 값을 가지게 된다. ( 그림1을 보고 충분히 생각해보면 왜 고정된 Embedding Vector 값이 나오는지 알 수 있을 것이다. )
그리고 Static Word Embedding 에서는 Shallow Neural Net을 사용해서 학습을 진행했었다.
Shallow Neural Net은 LSTM이나 RNN과 같이 순환 신경망 계열이 아니기 때문에 문맥 정보가 반영되지 않고 학습이 진행된다.
Contextual Language Model
Semi-Supervised Sequence Learning, Google, 2015
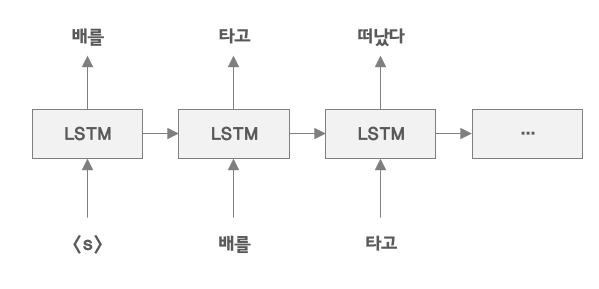
- Shallow Neural Net이 아닌 RNN, LSTM, GRU와 같은 순환신경망은 이전 정보를 반영해서 학습을 진행한다.
ELMo : Deep Contextual Word Embeddings, AI2&University of Washington, 2017
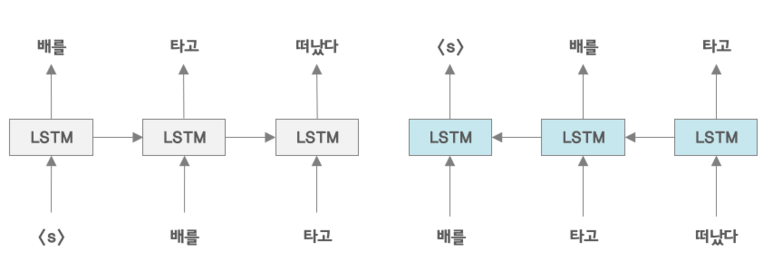
문장의 좌측에서 우측으로 우측에서 좌측으로 따로 따로 학습한다.
왜냐하면 문맥정보를 조금더 많이 반영하기 위해서 전->후 뿐만 아니라 후->전으로도 학습을 진행한다.
GPT : Improving Language Understanding by Generative Pre-Training, OpenAI, 2018
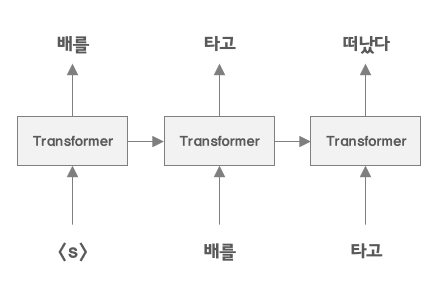
- LSTM이 아닌 Transformer를 사용해 학습을 진행한다.
- LSTM이 아닌 Transformer를 사용해 학습을 진행한다.
BERT
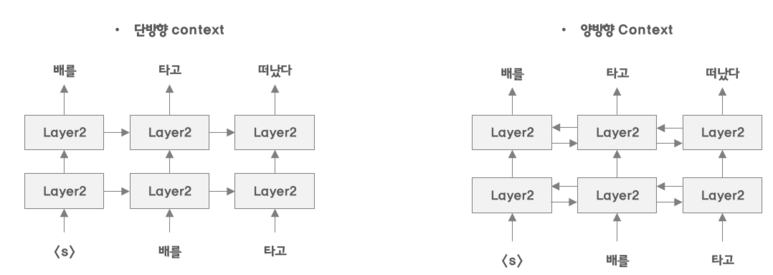
BERT는 GPT와 같이 Transformer를 이용하여 ELMo와 같이 양방향으로 학습을 진행한다.
사람도 언어를 이해할 때 양방향으로 이해하기 때문에 양방향으로 학습을 진행하면 성능이 좋아질 것이라 가정. ( BERT의 가장 큰 특징이라고 할 수 있다. )
ELMo와는 다르다. ELMo는 단방향으로 좌측 우측 각 각 학습하는 것이고 BERT는 양방향으로 동시에 학습을 진행하는 것이다.
하지만 양방향 학습을 하게 되면 단어가 자기 자신을 참조하는 문제가 발생한다.
“However, it is not possible to train bidirectional models by simply conditioning each word on its previous and next words, since this would allow the word that’s being predicted to indirectly “see itself” in a multi-layer model.”
예를 들어 “배를 타고 떠났다.”라는 문장이 있고 단방향 학습을 진행한다고 가정해보자.
“타고” 라는 단어를 학습할 때 “배를”이라는 단어만을 사용해서 학습을 진행한다.
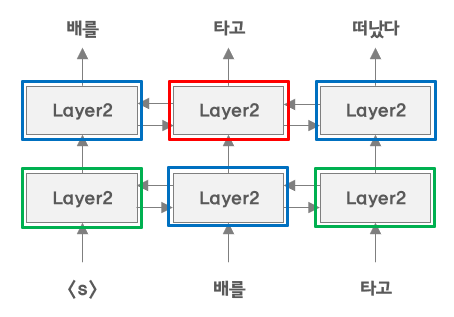
자기 자신을 참조할 일이 전혀 없다.(그림5)를 보게 되면 빨간 박스 부분 학습에 영향을 미치는 Layer는 파란색 박스 밖에 없다.
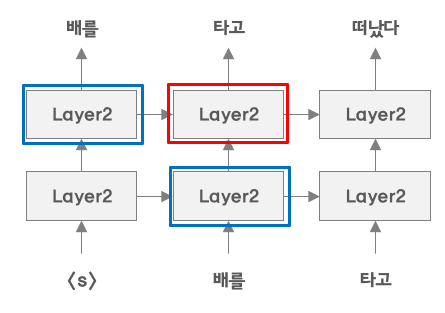
하지만 양방향 학습 같은 경우에는 영향을 미친다.
(그림6) 을 보면 빨간 박스에 직접적으로 영향을 미치는 것들은 파란색 박스이다.
하지만 파란색 박스에 초록색 박스 또한 영향을 미치고 있다.
“타고”라는 단어 또한 직접적이지는 않지만 간적적으로 학습에 영향을 미친다는 것이다.
BERT 특징
Masked LM
(그림7)과 같이 자기 자신을 참조하는 문제를 해결하기 위해 MASK를 씌워 학습을 진행한다.
이러한 방법이 오래전부터 문맥을 파악하는데 제시되었던 방법이라고 한다.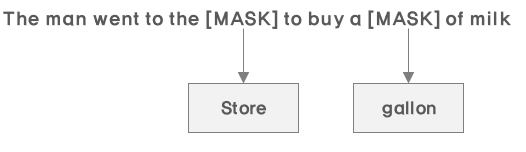
Masked LM을 사용하게 되면 또 다른 문제가 발생하게 된다.
실제 Fine-tuning과정에 학습 데이터에는 Mask toeknd이 존재하지 않는다는 것이다.
문장에 MASK를 씌우는 거는 Pre-trained 학습에서만 하지 실제 fine-tuning 할 때는 씌우지 않기 때문에 간극이 발생할 것이라 생각했다고 한다.
그에 대한 해결책으로 Mask token의 80%는 mask로 10%는 random word로 10%는 unchanged word로 넣어준다. ( 즉, 일부러 Noise를 넣음으로서 너무 Deep 한 모델에서 발생할 수 있는 Over-fitting문제를 회피하도록 의도하였다 )
예를 들면 아래와 같이 진행했다.
Mask token의 80% : 내 개는 크다 -> 내 개는 [MASK]
Mask token의 10% : 내 개는 크다 -> 내 개는 사과
Mask token의 10% : 내 개는 크다 -> 내 개는 크다
Next Sentence Prediction
BERT는 11개의 NLP Task에 대응하려고 했다.
하지만 11개의 Task 중에는 QA, QQ’similarity 등 문장에 대한 Task도 존재했다.
그래서 Next Sentence Prediction을 추가하여 범용성을 높이려고 했다.
예를 들면 다음과 같다.
Input = [CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label = IsNextInput = [CLS] the man went to [MASK] store [SEP] penguin [MASK] are flight
Label = NotNext첫번째 문장과 두번째 문장을 입력값으로 넣어 앞 뒤 문장이 연속되는 문장인지 분류하는 학습을 추가로 진행하였다.
BERT 모델
Model Input
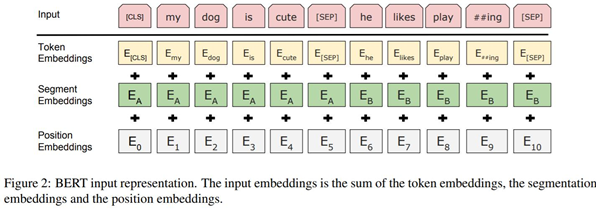
입력값의 형태는 하나의 문장이 입력값이 될 수도 있고, 두개의 문장 쌍 ( 예를 들면 Q&A )가 입력값이 될 수 있다.
e = self.tok_embed(x) + self.pos_embed(pos) + self.seg_embed(seg)
Token Embedding : Glove, Word2vec, Fasttext와 같은 것을 사용해 Vector 값을 가져온다.
Segment Embedding : 단어가 첫번째 문장에 속하는지 두번째 문장에 속하는지 알려준다.
[ 0 0 0 0 0 1 1 1 1 ] 과 같이 표현하며 해당 Vector를 Token Embedding 차원수와 같게 맞추어 임베딩 해준다.Positional Embedding : 각 단어가 첫번째인지 두번째인지를 의미하는 Embedding 값이다. 마찬가지로 Token Embedding의 차원수와 맟춰 임베딩 한 후 더해준다.
Encoder Block
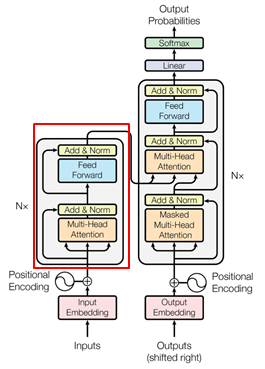
Transformer는 encode-decoder 구조로 decoder에서 loss function을 계산해서 trainin을 진행한다.
BERT에서는 Decoder 부분은 사용하지 않고 Encoder 부분만 사용을 한다. ( 붉은색 박스 부분 )
BERT는 N개의 encoder 블록을 사용한다. ( Base 모델은 12개, Large 모델은 24개로 구성 )
인코더 블록의 수가 많을수록 단어 사이의 복잡한 관계를 더 잘 포찰할 수 있다.
Pre-training Procedure
학습 데이터 : BooksCorpus(800M) + English Wikipedia(2,500M)위키 피디아의 경우 list, tables, header를 모두 제외하고 text만 사용
Batch size : 131,072 단어1Batch : 256 sequence x 512 words = 128,000 words 학습1Batch : 1024 sequence x 128 words = 131,072 words 학습
전체 step은 1,000,000번 으로 33억개의 단어 corpus에 대해서 대략 40 epoch 정도 학습
Dropout : 0.1 로 모든 레이어에 적용
Activate function : gelu
BERT-Base : 12-layer, 768-hidden, 12-head
BERT-Large : 24-layer, 1024-hidden, 16-head
Find-tuning Procedure
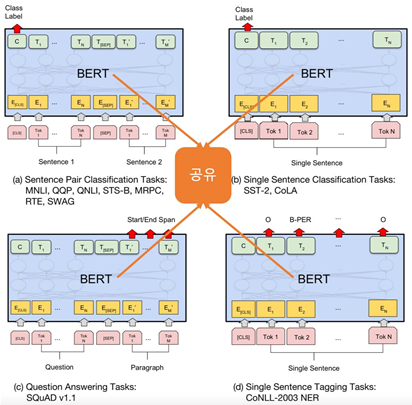
4개 정도 type의 언어 모델링 task를 만들고 output layer의 형태만 바꿔서 핵심 엔진인 BERT의 parameter 공유한다.
기본적으로 Transformer Encoder 부분의 Weight 는 Freeze 하고 추가적으로 하나의 Fully Connected Layer를 설계하여 우리가 원하는 Label 에 맞게 훈련하는 형태로 진행한다.
Result
BERT 결과 종합
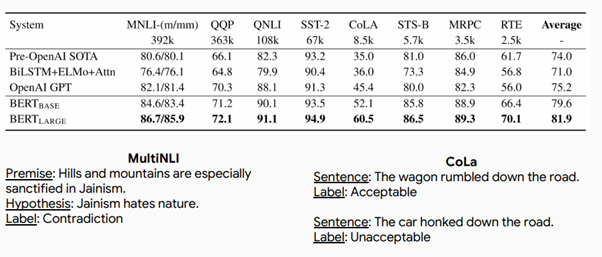
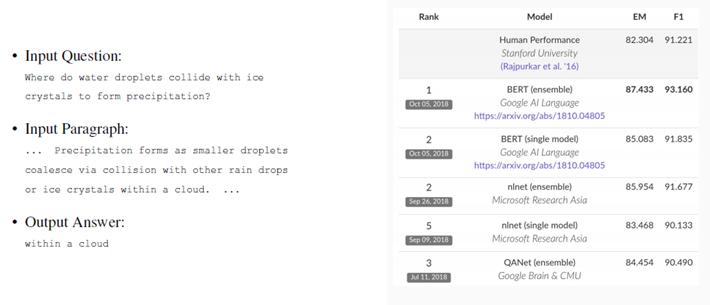
공부할 때 참고했던 URL
[URL] : https://reniew.github.io/47/
- 가장 Basic하게 설명되어 있는 페이지
[URL] : https://www.slideshare.net/deepseaswjh/rnn-bert
- 짧게 짧게 흐름 위주로 설명을 했다.
[URL] : http://www.modulabs.co.kr/DeepLAB_Paper/21074
- 모두의 연구소 자료
- 구체적으로 예시를 들어 설명해서 좋았다
-
- transformer에 대한 설명이 자세하게 되어 있어서 너무 좋았다.
- Attention 감 잡는데 굉장히 많은 도움이 되었다.
[URL] : http://docs.likejazz.com/bert/
- Basic 하게 설명되어 있다.
-
- 글쓴이의 해석이 들어가 있다. 도움이 되었다.
[URL] : https://www.facebook.com/groups/TensorFlowKR/permalink/767590103582050/
- 정말 깔끔 담백하게 정리되어 있다.
- 처음에 봤을 때는 잘 이해가 되지 않았지만 이해하고 보니까 이렇게 담백하게 표현할 수 있을까 싶다.
[URL] : https://github.com/huggingface/pytorch-pretrained-BERT#Fine-tuning-with-BERT-running-the-examples
- BERT를 사용해볼 수 있는 github
- 실제 돌려보니까 정말 이해가 잘 되었다.
-
- 코드와 함께 설명되어 있는 매우 희귀하고 좋은 자료
[URL] : https://medium.com/dissecting-bert/dissecting-bert-part-1-d3c3d495cdb3
- BERT와 Transformer를 잘 설명했다.
[URL] : http://gluon-nlp.mxnet.io/examples/sentence_embedding/bert.html
- 마찬가지로 코드와 함께 설명되어 있다.
